搜索到
157
篇与
的结果
-
 类的加载 加载将class字节码文件加载到内存中,并将这些静态数据转换为方法区的运行时数据结构,然后生成一个代表这个类的java.lang.Class对象链接将Java类的二进制代码合并到JVM的运行状态之中的过程验证:确保加载的类信息符合JVM规范准备:正式为类变量(static)分配内存并设置类变量默认初始值的阶段,这些内存都将在方法区中进行分配解析:虚拟机常量池内的符号引用(常量名)替换为直接引用(地址)的过程初始化执行类构造器<clinit>()方法的过程,类构造器<clinit>()方法是由编译器自动收集类中所有类变量的赋值动作和静态代码块中的赋值语句产生的。(类构造器构造类的信息,不是构造该类对象的构造器)当初始化一个类的时候,如果发现其父类还没有进行初始化,则需要先触发其父类的初始化虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确加锁和同步
类的加载 加载将class字节码文件加载到内存中,并将这些静态数据转换为方法区的运行时数据结构,然后生成一个代表这个类的java.lang.Class对象链接将Java类的二进制代码合并到JVM的运行状态之中的过程验证:确保加载的类信息符合JVM规范准备:正式为类变量(static)分配内存并设置类变量默认初始值的阶段,这些内存都将在方法区中进行分配解析:虚拟机常量池内的符号引用(常量名)替换为直接引用(地址)的过程初始化执行类构造器<clinit>()方法的过程,类构造器<clinit>()方法是由编译器自动收集类中所有类变量的赋值动作和静态代码块中的赋值语句产生的。(类构造器构造类的信息,不是构造该类对象的构造器)当初始化一个类的时候,如果发现其父类还没有进行初始化,则需要先触发其父类的初始化虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确加锁和同步 -
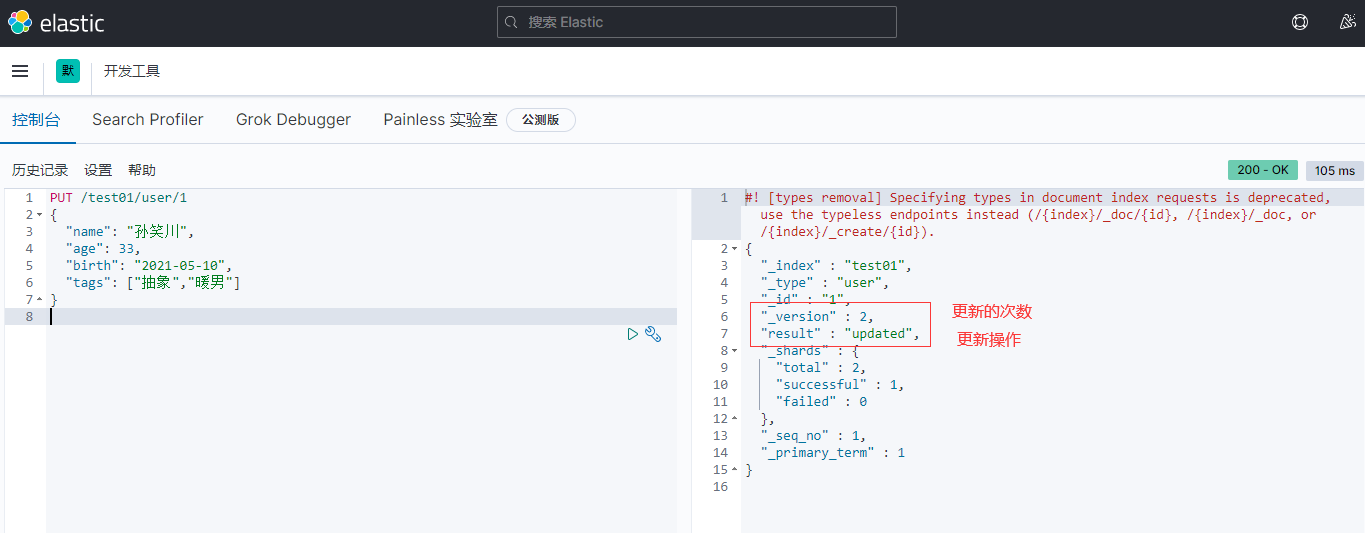
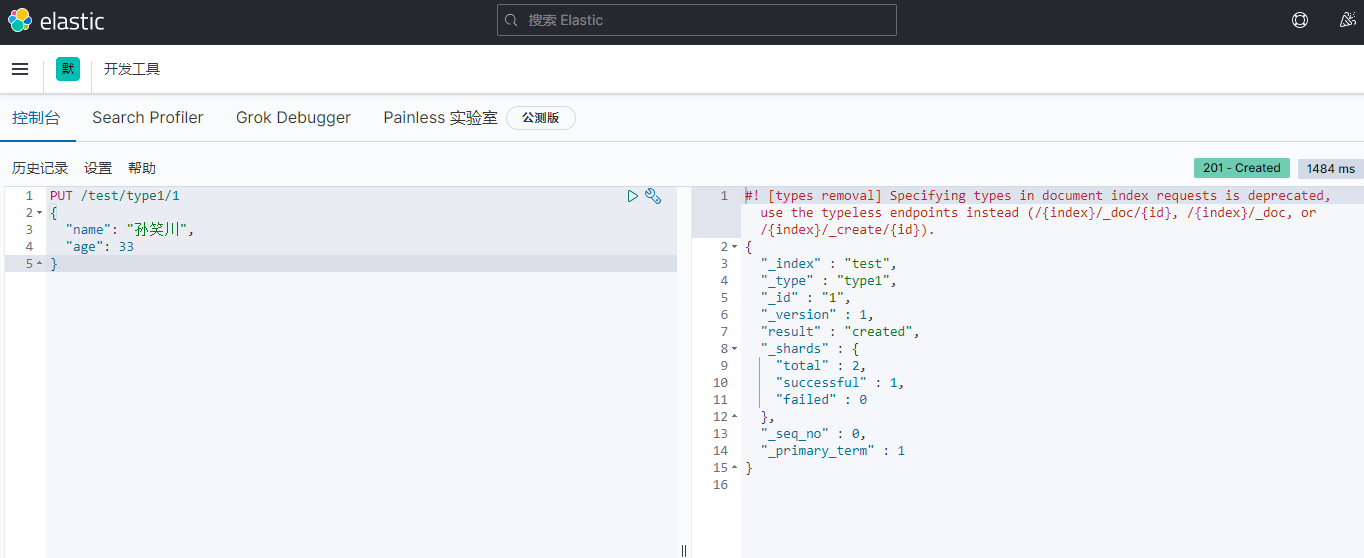
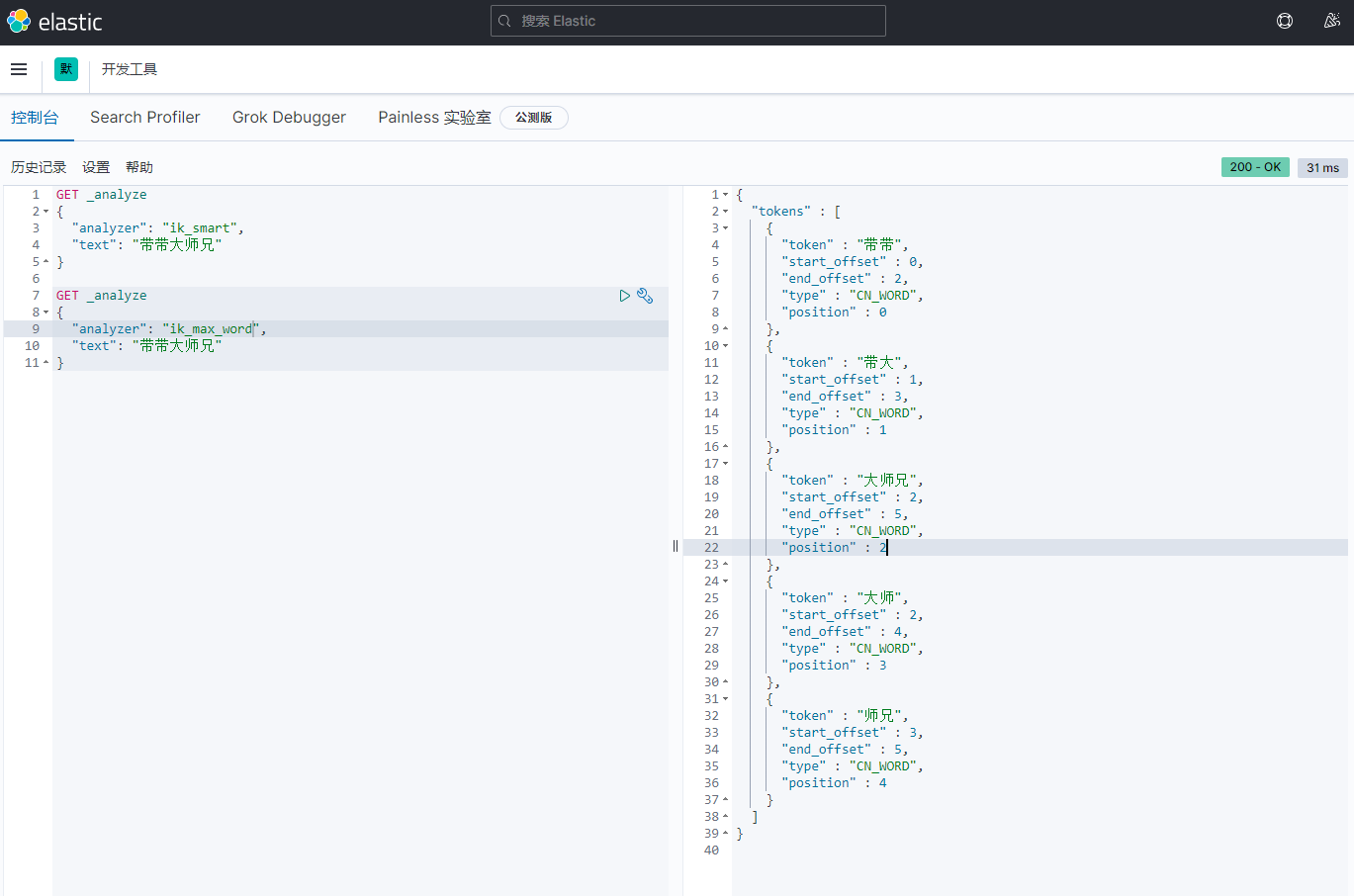
关于文档的基本操作 基本操作1、添加数据PUT /test01/user/1 { "name": "孙笑川", "age": 33, "birth": "2021-05-10", "tags": ["抽象","带师兄"] }2、获取数据GET /test01/user/13、更新数据 PUT4、POST 更新(推荐使用)5、搜索简单搜索复杂搜索select(排序,分页,高亮,模糊查询,精准查询)//查询参数体使用json构建 GET test01/user/_search { "query": { "match": { "name": "孙笑川" } } }结果过滤:排序:GET test01/user/_search { "query": { "match": { "name": "孙笑川" } }, "sort": [ { "age": { "order": "asc" } } ] }分页: //from等同于pageNum //size等同于pageSize GET test01/user/_search { "query": { "match": { "name": "孙笑川" } }, "sort": [ { "age": { "order": "asc" } } ], "from": 0, "size": 5 }布尔值多条件查询:must (and) 所有的条件都要匹配 where id = 1 and age = 10should (or) 条件匹配 where id = 1 or age = 10must_not (not)过滤器 filtergt # 大于 gte # 大于等于 lt # 小于 lte # 小于等于匹配多个条件精确查询term 通过倒排索引指定的词条进行精确查询分词term 直接精确查询match 查询时会使用分词器解析(先分析文档,再通过分析的文档进行查询)两个类型 text(会被分词器解析) keyword(不会被分词器解析)PUT test02 { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } } PUT test02/_doc/1 { "name": "text keyword字段类型测试", "desc": "text keyword字段类型测试 desc" } PUT test02/_doc/2 { "name": "text keyword字段类型测试", "desc": "text keyword字段类型测试 desc02" } GET _analyze { "analyzer": "keyword", "text": "text keyword字段类型测试" } GET _analyze { "analyzer": "standard", "text": "text keyword字段类型测试" } GET test02/_search { "query": { "term": { "name": "测" } } } GET test02/_search { "query": { "term": { "desc": "text keyword字段类型测试 desc" } } } PUT test02/_doc/3 { "t1": "11", "t2": "2021-05-11" } PUT test02/_doc/4 { "t1": "22", "t2": "2021-05-11" } GET test02/_search { "query": { "bool": { "should": [ { "term": { "t1": "11" } }, { "term": { "t1": "22" } } ] } } }多个值匹配的精确查询高亮查询自定义高亮格式
-
-
-
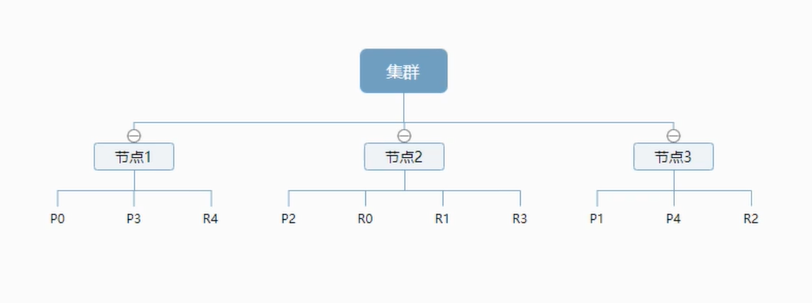
ElasticSearch相关概念 es与关系型数据库对比Relational DBElastic Search数据库(database)索引(indices)表(table)types(类型)(es8.0弃用)行(rows)documents(文档)字段(columns)fieldses(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档又包含多个字段(列)。物理设计:es在后台把每个索引划分成多个分片,每份分片可以在集群中的不同服务器间迁移逻辑设计:一个索引类型中包含多个文档,例如:文档1、文档2,当要搜索一篇文档时,大致流程为:索引 ---> 类型 ---> 文档ID(ID不必是整数,实际上是一个字符串)文档es是面向文档的,也就是说索引和搜索数据的最小单位是文档,其包含有几个重要属性:自我包含,一篇文档同时包含字段和对应的值,即key:value层次型的:一个文档中包含自文档(json对象,fastjson进行自动转换)灵活的结构:文档不依赖预先定义的模式,在关系型数据库中,要提前定义字段才能使用,而在es中,可以忽略一个字段或动态的添加一个新的字段在es中,每个字段的类型非常重要,它会保存字段和类型之间的映射及其他的设置,这种映射具体到每个映射的每种类型,这也是为什么在es中,类型有时候也称为映射类型类型类型是文档的逻辑容器(就像关系型数据库,表格是行的容器),类型中对于字段的定义称为映射,比如name映射为字符串类型。先定义好字段,再使用索引es中的索引就是数据库,索引是映射类型的容器,是一个非常大的文档集合,存储映射类型和其他设置,再被存放到各个分片上物理设计:节点和分片如何工作一个集群至少有一个节点,而一个节点就是一个es进程,创建索引时,默认5个分片(primary shard,主分片),每一个主分片会有一个副本(replica shard,复制分片)以上图3个节点的集群为例,可以看出主分片和对应的复制分片都不会在同一个节点内,可以避免级联故障。实际上,一个分片是一个Lucence索引,一个包含倒排索引的文件目录,倒排索引使得es可以在不扫描全部文档的情况下,检索出需要的内容。倒排索引es使用的是倒排索引结构,采用Lucence倒排索引作为底层。这种结构适用于快速全文搜索,一个索引由文档中所有不同的列表构成,对于每一个词,都有一个包含它的文档列表。例1:现在有两个文档,每个文档包含以下内容:# 文档1 Study every day,good good up to forever # 文档2 To forever,study every day, good good up为了创建倒排索引,先要将每个文档拆分成独立的词(或称为词条、tokens),然后创建一个包含所有不重复的词条的排序列表 文档1文档2Study√×To×√every√√forever√√day√√study×√good√√every√√to√×up√√现在试图搜索to forever,只需要查看包含每个词条的文档 文档1文档2to√×forever√√total21两个文档都匹配,但第一个文档比第二个文档匹配度更高,没有别的条件时,返回这两个包含关键字的文档例2:通过博客标签来搜索博客文章现搜索包含python标签的文章,相较于搜索原始数据,现只需要搜索标签这一栏,即可更快的获取文章id
-
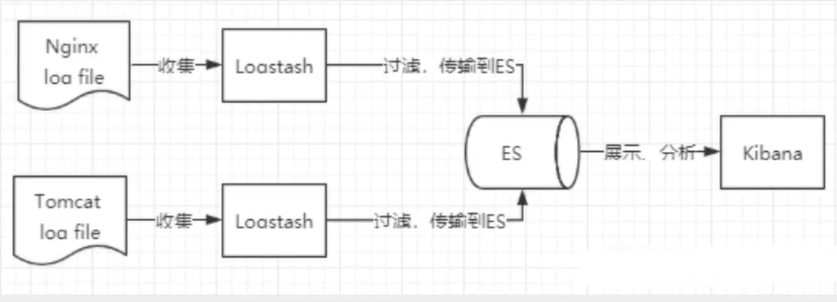
Elastic Search 一、概述Elastic Search简称es,是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据,可以使用java开发并使用Lucence作为其核心来实现所有索引和搜索的功能,其目的是通过简单的RESTfull API来隐藏Lucence的复杂性,从而让全文搜索变得简单。二、ELKELK是Elastic Search、Logstash、Kibana的首字母简称,也成为Elastic Stack。其中Elastic Search是一个基于Lucence、分布式、通过Restfull方式进行交互的近实时搜索平台框架;Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/rdis/elasticsearch/Kafka等);Kibana可以将elasticsearch的数据通过友好的页面展示出来。提供实时分析的功能。三、安装1、elasticsearch官网地址:https://www.elastic.co/cn/elasticsearch/# 跨域问题须在/config/elasticsearch.yml配置文件末尾添加 http.cors.enabled: true http.cors.allow-origin: "*"2、Kibana官网地址:https://www.elastic.co/cn/kibana注意:es和kibana的版本必须一致
-
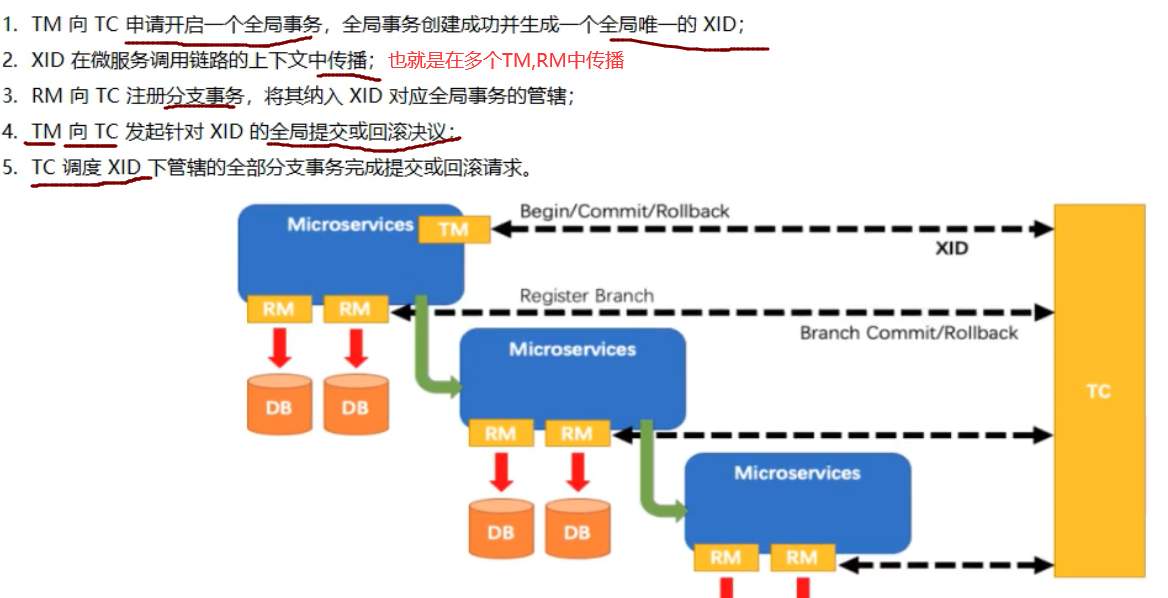
Seata分布式事务原理 1、TM开启分布式事务(TM向TC注册全局事务)2、按业务场景,编排数据库、服务等事务内的资源(RM向TC汇报资源准备状态)3、TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚)4、TC汇总事务信息,决定最终是提交还是回滚事务5、TC通知所有RM提交/回滚 资源,事务二阶段结束Seata提供了四个模式:AT、TCC、SAGA、XAAT模式两阶段提交协议的演变:一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源二阶段:提交异步化(能快速完成);回滚通过一阶段的回滚日志进行反向补偿一阶段:在一阶段,seata会拦截“业务SQL”:1、解析SQL语义,找到“业务SQL”要更新的业务数据,在业务数据被更新前,将其保存为before image2、执行“业务SQL”更新业务数据,更新之后将业务数据保存为after image3、最后生成行锁以上操作全部在一个数据库事务内完成,保证了一阶段操作的原子性二阶段:1、成功提交二阶段正常执行的话,只需将一阶段保存的快照数据和行锁删除,即可完成数据清理,因为“业务SQl”在一阶段已经在提交至数据库2、事务回滚二阶段如果出现异常,需要事务回滚,seata就需要回滚一阶段已经执行的“业务SQL”,还原业务数据;回滚方式使用before image还原业务数据,在还原之前需要做校验脏写,对比数据库当前的业务数据和after image数据快照,如果两份数据完全一致,就说明没有脏写,执行还原操作,如果不一致,就需要转人工处理
-
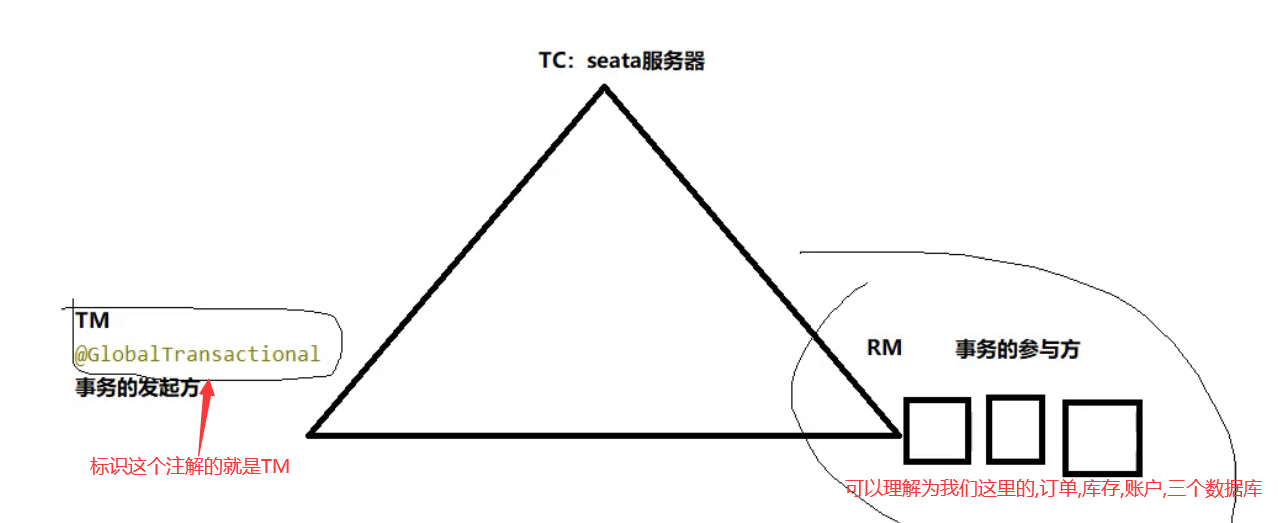
Seata seata是一个分布式的解决方案,致力于在微服务架构下提供高性能和简单易用的分布式微服务,官网:http://seata.io/zh-cn/一、三组概念TC 事务协调者:维护全局和分支事务的状态,驱动全局事务提交或回滚TM 事务管理器:定义全局事务的范围:开始、提交、回滚RM 资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚二、安装GitHub地址:https://github.com/seata/seata(以Nacos 2.0、Seata 1.4.2为例)修改配置文件1、/conf/file.conf (注意与1.0之前的版本区分,1.0之后可以在yml文件中指定service配置)修改数据库模式(使用数据库存储事务信息)和数据源2、/conf/registry.conf3、mysql建表1、新建seata数据库2、运行mysql.sql注意:建表sql在/conf/REDME.md文件中,点击server出现存放sql的github地址:https://github.com/seata/seata/tree/develop/script/server4、启动先启动Nacos再启动Seata(bin/seata-server.bat)三、业务测试1、业务说明创建三个微服务:订单---库存---账户大致流程:当用户下单时,订单服务创建订单,远程调用库存服务扣减库存,再通过远程调用账户服务来扣减账户余额,最后在订单服务中修改订单状态为已完成。2、数据库建表创建三个数据库seata_order(订单),seata_storage(库存),seata_account(账户)创建对应的表-- t_order DROP TABLE IF EXISTS `t_order`; CREATE TABLE `t_order` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `user_id` bigint(11) NULL DEFAULT NULL COMMENT '用户id', `product_id` bigint(11) NULL DEFAULT NULL COMMENT '产品id', `count` int(11) NULL DEFAULT NULL COMMENT '数量', `money` decimal(11, 0) NULL DEFAULT NULL COMMENT '金额', `status` int(1) NULL DEFAULT NULL COMMENT '订单状态:0:创建中; 1:已完结', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 14 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- t_storage DROP TABLE IF EXISTS `t_storage`; CREATE TABLE `t_storage` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `product_id` bigint(11) NULL DEFAULT NULL COMMENT '产品id', `total` int(11) NULL DEFAULT NULL COMMENT '总库存', `used` int(11) NULL DEFAULT NULL COMMENT '已用库存', `residue` int(11) NULL DEFAULT NULL COMMENT '剩余库存', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; INSERT INTO `t_storage` VALUES (1, 1, 100, 0, 100); -- t_account DROP TABLE IF EXISTS `t_account`; CREATE TABLE `t_account` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT 'id', `user_id` bigint(11) NULL DEFAULT NULL COMMENT '用户id', `total` decimal(10, 0) NULL DEFAULT NULL COMMENT '总额度', `used` decimal(10, 0) NULL DEFAULT NULL COMMENT '已用余额', `residue` decimal(10, 0) NULL DEFAULT 0 COMMENT '剩余可用额度', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; INSERT INTO `t_account` VALUES (1, 1, 1000, 0, 1000);undo回滚日志表,三个库每个都需要创建一张回滚表,分别执行三次DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime(0) NOT NULL, `log_modified` datetime(0) NOT NULL, `ext` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;3、seata-order-servicepom<dependencies> <!-- API --> <dependency> <groupId>com.sw</groupId> <artifactId>cloud-api-commons</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <!--nacos--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--seata--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> <exclusions> <exclusion> <artifactId>seata-all</artifactId> <groupId>io.seata</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>io.seata</groupId> <artifactId>seata-spring-boot-starter</artifactId> <version>1.4.0</version> </dependency> <!--feign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <!--web-actuator--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--mysql-druid--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.16</version> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> </dependencies>ymlserver: port: 2001 spring: application: name: seata-order-service cloud: nacos: discovery: server-addr: localhost:8848 datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/seata_order?useSSL=true&serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8 username: root password: 123456 seata: enabled: true application-id: ${spring.application.name} # 自定义事务组名称 tx-service-group: test_tx_group service: vgroup-mapping: test_tx_group: default config: nacos: namespace: server-addr: 127.0.0.1:8848 group: SEATA_GROUP userName: "nacos" password: "nacos" registry: type: nacos nacos: application: seata-server server-addr: 127.0.0.1:8848 namespace: userName: "nacos" password: "nacos" feign: hystrix: enabled: false logging: level: io: seata: info启动类@SpringBootApplication(exclude = DataSourceAutoConfiguration.class) //取消自动创建数据源 @EnableDiscoveryClient @EnableFeignClients @MapperScan("com.sw.mapper") public class SeataOrderMain2001 { public static void main(String[] args) { SpringApplication.run(SeataOrderMain2001.class, args); } }pojo@Data @NoArgsConstructor @AllArgsConstructor public class Order implements Serializable { private Long id; private Long userId; private Long productId; private Integer count; private BigDecimal money; private Integer status; //订单状态:0:创建中;1:已完结 }mapper@Repository public interface OrderMapper { /** * 新建订单 * @param order */ @Insert("insert into t_order(id,user_id,product_id,count,money,status) " + "values(null,#{userId},#{productId},#{count},#{money},0)") void create(Order order); /** * 更新订单 * @param userId * @param status */ @Update("update t_order set status = 1 " + "where user_id=#{userId} and status = #{status}") void update(@Param("userId")Long userId, @Param("status")Integer status); }serviceOrderServicepublic interface OrderService { void create(Order order); }StorageService@FeignClient("seata-storage-service") public interface StorageService { @PostMapping("/storage/decrease") CommonResult decrease(@RequestParam("productId")Long productId, @RequestParam("count")Integer count); }AccountService@FeignClient("seata-account-service") public interface AccountService { @PostMapping("/account/decrease") CommonResult decrease(@RequestParam("userId")Long userId, @RequestParam("money")BigDecimal money); }service实现@Service @Slf4j public class OrderServiceImpl implements OrderService { @Autowired private OrderMapper orderMapper; @Autowired private AccountService accountService; @Autowired private StorageService storageService; @Override public void create(Order order) { //1.新建订单 log.info("===开始新建订单==="); orderMapper.create(order); //2.扣减库存 log.info("===订单微服务调用库存==="); storageService.decrease(order.getProductId(), order.getCount()); log.info("===订单微服务调用库存,库存数量操作结束==="); //3.扣减账户 log.info("===订单微服务调用账户余额==="); accountService.decrease(order.getUserId(), order.getMoney()); log.info("===订单微服务调用账户余额,账户余额操作结束==="); //4.修改订单状态 log.info("===修改订单状态,开始==="); //从 0 到 1,1代表已经完成 orderMapper.update(order.getUserId(), 0); log.info("===修改订单状态,操作结束==="); log.info("订单操作完成(*^_^*)"); } }controller@RestController @RequestMapping("/order") public class OrderController { @Autowired private OrderService orderService; @GetMapping("/create") public CommonResult create(Order order){ orderService.create(order); return new CommonResult(200, "订单创建成功!"); } } config主启动类排除了数据源配置,此处需指定数据源代理@Configuration public class DataSourceProxyConfig { @Bean @ConfigurationProperties(prefix = "spring.datasource") public DataSource druidDataSource(){ return new DruidDataSource(); } @Primary @Bean("dataSource") public DataSourceProxy dataSourceProxy(DataSource dataSource){ return new DataSourceProxy(dataSource); } }4、seata-storage-serviceymlserver: port: 2002 spring: application: name: seata-storage-service cloud: nacos: discovery: server-addr: localhost:8848 datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/seata_storage?useSSL=true&serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8 username: root password: 123456 seata: enabled: true application-id: ${spring.application.name} tx-service-group: test_tx_group service: vgroup-mapping: test_tx_group: default config: nacos: namespace: server-addr: 127.0.0.1:8848 group: SEATA_GROUP userName: "nacos" password: "nacos" registry: type: nacos nacos: application: seata-server server-addr: 127.0.0.1:8848 namespace: userName: "nacos" password: "nacos" feign: hystrix: enabled: false logging: level: io: seata: infomapper@Repository public interface StorageMapper { /** * 扣减库存信息 * @param productId * @param count */ @Update("update t_storage " + "set used = used + #{count}," + "residue = residue - #{count} "+ "where product_id = #{productId}" ) void decrease(@Param("productId")Long productId, @Param("count")Integer count); }servicepublic interface StorageService { void decrease(Long productId, Integer count); }service实现@Slf4j @Service public class StorageServiceImpl implements StorageService { @Autowired private StorageMapper storageMapper; @Override public void decrease(Long productId, Integer count) { log.info("===storage-service 开始扣减库存==="); storageMapper.decrease(productId, count); log.info("===storage-service 扣减库存操作结束==="); } }其他配置同理order微服务模块的5、seata-account-servicemapper@Repository public interface AccountMapper { /** * 扣减账户余额 * @param userId * @param money */ @Update("update t_account set "+ "used = used + #{money},"+ "residue = residue - #{money} "+ "where user_id = #{userId}" ) void decrease(@Param("userId")Long userId, @Param("money") BigDecimal money); }其他配置同理storage微服务模块的创建6、不添加全局事务管理测试seata-account-service模块1、手动模拟超时@Slf4j @Service public class AccountServiceImpl implements AccountService { @Autowired private AccountMapper accountMapper; @Override public void decrease(Long userId, BigDecimal money) { log.info("===account-service 开始扣减账户余额==="); //模拟超时异常 try { TimeUnit.SECONDS.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); } accountMapper.decrease(userId, money); log.info("===account-service 扣减账户余额操作结束==="); } }浏览器输入http://localhost:2001/order/create?userId=1&productId=1&count=10&money=100报错Read TimeOut异常:此时数据库的状态:7、开启全局事务在order模块中添加全局事务注解@GlobalTransactional使用同样的方法测试,发生调用超时异常后,数据库中被修改的数据回滚到了操作之前的状态