


1. 环境准备
pip install keras
pip install tensorflow
pip install scipy2. 流程
(1)模型训练
根据已有的图片样本训练模型(车位上是否有车)
(2)数据处理
- 背景过滤
- Canny 边缘检测
- 停车场区域提取(去掉冗余部分)
- 霍夫变换(检测直线,即车位线)
- 以列为单位划分每一排的停车位
- 提取车位数据
- 生成 CNN 预测图
(3)获取结果
通过训练好的模型及车位数据字典(车位上是否有车),判断车位是否为空
3. 代码
以停车场俯瞰照片为例
项目结构

停车场俯瞰图


keras_train.py
import os from tensorflow.keras.applications.vgg16 import VGG16 from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.models import Model from tensorflow.keras.layers import Flatten, Dense from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping from tensorflow.keras import optimizers files_train = 0 files_validation = 0 cwd = os.getcwd() folder = "train_data/train" for sub_folder in os.listdir(folder): path, dirs, files = next(os.walk(os.path.join(folder, sub_folder))) files_train += len(files) folder = "train_data/test" for sub_folder in os.listdir(folder): path, dirs, files = next(os.walk(os.path.join(folder, sub_folder))) files_validation += len(files) print(files_train, files_validation) img_width, img_height = 48, 48 train_data_dir = "train_data/train" validation_data_dir = "train_data/test" nb_train_samples = files_train nb_validation_samples = files_validation batch_size = 32 epochs = 15 num_classes = 2 model = VGG16(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3)) for layer in model.layers[:10]: layer.trainable = False x = model.output x = Flatten()(x) predictions = Dense(num_classes, activation='softmax')(x) model_final = Model(inputs=model.input, outputs=predictions) model_final.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(learning_rate=0.0001, momentum=0.9), metrics=["accuracy"]) train_datagen = ImageDataGenerator( rescale=1. / 255, horizontal_flip=True, fill_mode='nearest', zoom_range=0.1, width_shift_range=0.1, height_shift_range=0.1, rotation_range=5) test_datagen = ImageDataGenerator( rescale=1. / 255, horizontal_flip=True, fill_mode='nearest', zoom_range=0.1, width_shift_range=0.1, height_shift_range=0.1, rotation_range=5) train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode='categorical') validation_generator = test_datagen.flow_from_directory( validation_data_dir, target_size=(img_height, img_width), class_mode='categorical') checkpoint = ModelCheckpoint( 'car1.h5', monitor="val_accuracy", verbose=1, save_best_only=True, save_weights_only=False, save_freq='epoch' ) early = EarlyStopping( monitor='val_accuracy', min_delta=0, patience=10, verbose=1, mode='auto' ) history = model_final.fit( train_generator, steps_per_epoch=nb_train_samples // batch_size, epochs=epochs, validation_data=validation_generator, validation_steps=nb_validation_samples // batch_size, callbacks=[checkpoint, early] )Parking.py
import os import numpy as np import cv2 import matplotlib.pyplot as plt class Parking: def show_images(self, images, cmap=None): cols = 2 rows = (len(images) + 1) // cols plt.figure(figsize=(15, 12)) for i, image in enumerate(images): plt.subplot(rows, cols, i + 1) cmap = "gray" if len(image.shape) == 2 else cmap plt.imshow(image, cmap=cmap) plt.xticks([]) plt.yticks([]) plt.tight_layout(pad=0, h_pad=0, w_pad=0) plt.show() def cv_show(self, title, img): cv2.imshow(title, img) cv2.waitKey(0) cv2.destroyAllWindows() def select_rgb_white_yellow(self, image): # 过滤背景 lower = np.uint8([120, 120, 120]) upper = np.uint8([255, 255, 255]) # lower_red 和高于 upper_red 的部分分别设置为0,lower_red ~ upper_red 之间的值设置为255,相当于过滤背景 white_mask = cv2.inRange(image, lower, upper) self.cv_show("white_mask", white_mask) masked = cv2.bitwise_and(image, image, mask=white_mask) self.cv_show("masked", masked) return masked def convert_gray_scale(self, image): return cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) def detect_edges(self, image, low_threshold=50, high_threshold=200): return cv2.Canny(image, low_threshold, high_threshold) def filter_region(self, image, vertices): # 剔除冗余部分 mask = np.zeros_like(image) if len(mask.shape) == 2: cv2.fillPoly(mask, vertices, 255) self.cv_show("mask", mask) return cv2.bitwise_and(image, mask) def select_region(self, image): # 手动选择区域 rows, cols = image.shape[:2] pt_1 = [cols * 0.05, rows * 0.90] pt_2 = [cols * 0.05, rows * 0.70] pt_3 = [cols * 0.30, rows * 0.55] pt_4 = [cols * 0.6, rows * 0.15] pt_5 = [cols * 0.90, rows * 0.15] pt_6 = [cols * 0.90, rows * 0.90] vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32) point_img = image.copy() point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2RGB) for point in vertices[0]: cv2.circle(point_img, (point[0], point[1]), 10, (0, 0, 255), 4) self.cv_show("point_img", point_img) return self.filter_region(image, vertices) def hough_lines(self, image): # 输入的图像:边缘检测后的结果 # rho:距离精度 # theta:角度精度 # threshold”超过设定阈值才被检测出线段 # minLineLength:线的最短长度,比这个短的都被忽略,MaxLineCap(两条直线之间的最大间隔,小于此值,认为是一条直线) return cv2.HoughLinesP(image, rho=0.1, theta=np.pi / 10, threshold=15, minLineLength=9, maxLineGap=4) def draw_lines(self, image, lines, color=[255, 0, 0], thickness=2, make_copy=True): # 过滤霍夫变换检测到直线 if make_copy: image = np.copy(image) cleaned = [] for line in lines: for x1, y1, x2, y2 in line: if abs(y2 - y1) <= 1 and abs(x2 - x1) >= 25 and abs(x2 - x1) <= 55: cleaned.append((x1, y1, x2, y2)) cv2.line(image, (x1, y1), (x2, y2), color, thickness) print(" No lines detected: ", len(cleaned)) return image def identify_blocks(self, image, lines, make_copy=True): if make_copy: new_image = np.copy(image) # 过滤部分直线 cleaned = [] for line in lines: for x1, y1, x2, y2 in line: if abs(y2 - y1) <= 1 and abs(x2 - x1) >= 25 and abs(x2 - x1) <= 55: cleaned.append((x1, y1, x2, y2)) # 对直线 按照x1 进行排序 import operator list1 = sorted(cleaned, key=operator.itemgetter(0, 1)) # 寻找多列,即每列看作是一排车 clusters = {} dIndex = 0 clus_dist = 10 for i in range(len(list1) - 1): distance = abs(list1[i + 1][0] - list1[i][0]) if distance <= clus_dist: if not dIndex in clusters.keys(): clusters[dIndex] = [] clusters[dIndex].append(list1[i]) clusters[dIndex].append(list1[i + 1]) else: dIndex += 1 # 获取坐标 rects = {} i = 0 for key in clusters: all_list = clusters[key] cleaned = list(set(all_list)) if len(cleaned) > 5: cleaned = sorted(cleaned, key=lambda tup: tup[1]) avg_y1 = cleaned[0][4] avg_y2 = cleaned[-1][5] avg_x1 = 0 avg_x2 = 0 for tup in cleaned: avg_x1 += tup[0] avg_x2 += tup[2] avg_x1 = avg_x1 / len(cleaned) avg_x2 = avg_x2 / len(cleaned) rects[i] = (avg_x1, avg_y1, avg_x2, avg_y2) i += 1 print("Num Parking Lanes: ", len(rects)) # 绘制列的矩形 buff = 7 for key in rects: tup_topLeft = (int(rects[key][0] - buff), int(rects[key][6])) tup_botRight = (int(rects[key][7] + buff), int(rects[key][8])) cv2.rectangle(new_image, tup_topLeft, tup_botRight, (0, 255, 0), 3) return new_image, rects def draw_parking(self, image, rects, make_copy=True, color=[255, 0, 0], thickness=2, save=True): if make_copy: new_image = np.copy(image) gap = 15.5 # 字典:一辆车位对应一个位置 spot_dict = {} tot_spots = 0 # 微调 adj_y1 = {0: 20, 1: -10, 2: 0, 3: -11, 4: 28, 5: 5, 6: -15, 7: -15, 8: -10, 9: -30, 10: 9, 11: -32} adj_y2 = {0: 30, 1: 50, 2: 15, 3: 10, 4: -15, 5: 15, 6: 15, 7: -20, 8: 15, 9: 15, 10: 0, 11: 30} adj_x1 = {0: -8, 1: -15, 2: -15, 3: -15, 4: -15, 5: -15, 6: -15, 7: -15, 8: -10, 9: -10, 10: -10, 11: 0} adj_x2 = {0: 0, 1: 15, 2: 15, 3: 15, 4: 15, 5: 15, 6: 15, 7: 15, 8: 10, 9: 10, 10: 10, 11: 0} for key in rects: tup = rects[key] x1 = int(tup[0] + adj_x1[key]) x2 = int(tup[2] + adj_x2[key]) y1 = int(tup[1] + adj_y1[key]) y2 = int(tup[3] + adj_y2[key]) cv2.rectangle(new_image, (x1, y1), (x2, y2), (0, 255, 0), 2) num_splits = int(abs(y2 - y1) // gap) for i in range(0, num_splits + 1): y = int(y1 + i * gap) cv2.line(new_image, (x1, y), (x2, y), color, thickness) if key > 0 and key < len(rects) - 1: # 竖直线 x = int((x1 + x2) / 2) cv2.line(new_image, (x, y1), (x, y2), color, thickness) # 计算数量 if key == 0 or key == (len(rects) - 1): tot_spots += num_splits + 1 else: tot_spots += 2 * (num_splits + 1) # 字典对应 if key == 0 or key == (len(rects) - 1): for i in range(0, num_splits + 1): cur_len = len(spot_dict) y = int(y1 + i * gap) spot_dict[(x1, y, x2, y + gap)] = cur_len + 1 else: for i in range(0, num_splits + 1): cur_len = len(spot_dict) y = int(y1 + i * gap) x = int((x1 + x2) / 2) spot_dict[(x1, y, x, y + gap)] = cur_len + 1 spot_dict[(x, y, x2, y + gap)] = cur_len + 2 print("total parking spaces: ", tot_spots, cur_len) if save: filename = "with_parking.jpg" cv2.imwrite(filename, new_image) return new_image, spot_dict def assign_spots_map(self, image, spot_dict, make_copy=True, color=[255, 0, 0], thickness=2): if make_copy: new_image = np.copy(image) for spot in spot_dict.keys(): (x1, y1, x2, y2) = spot cv2.rectangle(new_image, (int(x1), int(y1)), (int(x2), int(y2)), color, thickness) return new_image def save_images_for_cnn(self, image, spot_dict, folder_name='cnn_data'): for spot in spot_dict.keys(): (x1, y1, x2, y2) = spot (x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2)) # 裁剪 spot_img = image[y1:y2, x1:x2] spot_img = cv2.resize(spot_img, (0, 0), fx=2.0, fy=2.0) spot_id = spot_dict[spot] filename = "spot" + str(spot_id) + ".jpg" print(spot_img.shape, filename, (x1, x2, y1, y2)) cv2.imwrite(os.path.join(folder_name, filename), spot_img) def make_prediction(self, image, model, class_dictionary): # 预处理 img = image / 255. # 转换为 4D tensor image = np.expand_dims(img, axis=0) # 根据模型进行训练 class_predicted = model.predict(image) inID = np.argmax(class_predicted[0]) label = class_dictionary[inID] return label def predict_on_image(self, image, spot_dict, model, class_dictionary, make_copy=True, color=[0, 255, 0], alpha=0.5): if make_copy: new_image = np.copy(image) overlay = np.copy(image) self.cv_show("new_image", new_image) cnt_empty = 0 all_spots = 0 for spot in spot_dict.keys(): all_spots += 1 (x1, y1, x2, y2) = spot (x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2)) spot_img = image[y1:y2, x1:x2] spot_img = cv2.resize(spot_img, (48, 48)) label = self.make_prediction(spot_img, model, class_dictionary) if label == "empty": cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1) cnt_empty += 1 cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image) cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2) cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2) save = False if save: filename = "with_marking.jpg" cv2.imwrite(filename, new_image) self.cv_show("new_image", new_image) return new_image def predict_on_video(self, video_name, final_spot_dict, model, class_dictionary, ret=True): cap = cv2.VideoCapture(video_name) count = 0 while ret: ret, image = cap.read() count += 1 if count == 5: count = 0 new_image = np.copy(image) overlay = np.copy(image) cnt_empty = 0 all_spots = 0 color = [0, 255, 0] alpha = 0.5 for spot in final_spot_dict.keys(): all_spots += 1 (x1, y1, x2, y2) = spot (x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2)) spot_img = image[y1:y2, x1:x2] spot_img = cv2.resize(spot_img, (48, 48)) label = self.make_prediction(spot_img, model, class_dictionary) if label == "empty": cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1) cnt_empty += 1 cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image) cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2) cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2) cv2.imshow("frame", new_image) if cv2.waitKey(10) & 0xFF == ord("q"): break cv2.destroyAllWindows() cap.release()parking_test.py
from __future__ import division import matplotlib.pyplot as plt import cv2 import os, glob from keras.models import load_model from Parking import Parking import pickle cwd = os.getcwd() def img_process(test_images, park): white_yellow_images = list(map(park.select_rgb_white_yellow, test_images)) park.show_images(white_yellow_images) gray_images = list(map(park.convert_gray_scale, white_yellow_images)) park.show_images(gray_images) edge_images = list(map(lambda image: park.detect_edges(image), gray_images)) park.show_images(edge_images) roi_images = list(map(park.select_region, edge_images)) park.show_images(roi_images) list_of_lines = list(map(park.hough_lines, roi_images)) line_images = [] for image, lines in zip(test_images, list_of_lines): line_images.append(park.draw_lines(image, lines)) park.show_images(line_images) rect_images = [] rect_coords = [] for image, lines in zip(test_images, list_of_lines): new_image, rects = park.identify_blocks(image, lines) rect_images.append(new_image) rect_coords.append(rects) park.show_images(rect_images) delineated = [] spot_pos = [] for image, rects in zip(test_images, rect_coords): new_image, spot_dict = park.draw_parking(image, rects) delineated.append(new_image) spot_pos.append(spot_dict) park.show_images(delineated) final_spot_dict = spot_pos[1] print(len(final_spot_dict)) with open('spot_dict.pickle', 'wb') as handle: pickle.dump(final_spot_dict, handle, protocol=pickle.HIGHEST_PROTOCOL) park.save_images_for_cnn(test_images[0], final_spot_dict) return final_spot_dict def keras_model(weights_path): model = load_model(weights_path) return model def img_test(test_images, final_spot_dict, model, class_dictionary): for i in range(len(test_images)): predicted_images = park.predict_on_image(test_images[i], final_spot_dict, model, class_dictionary) def video_test(video_name, final_spot_dict, model, class_dictionary): name = video_name cv2.VideoCapture(name) park.predict_on_video(name, final_spot_dict, model, class_dictionary, ret=True) if __name__ == '__main__': images = [plt.imread(path) for path in glob.glob('images/*.jpg')] weights_path = "car1.h5" video = "video/parking_video.mp4" class_dictionary = {} class_dictionary[0] = "empty" class_dictionary[1] = "occupied" park = Parking() park.show_images(images) final_spot_dict = img_process(images, park) model = keras_model(weights_path) img_test(images, final_spot_dict, model, class_dictionary) # video_test(video, final_spot_dict, model, class_dictionary)结果


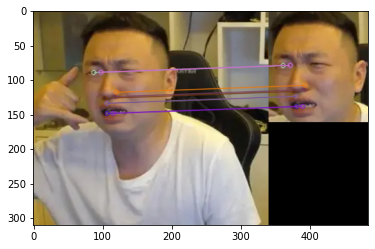
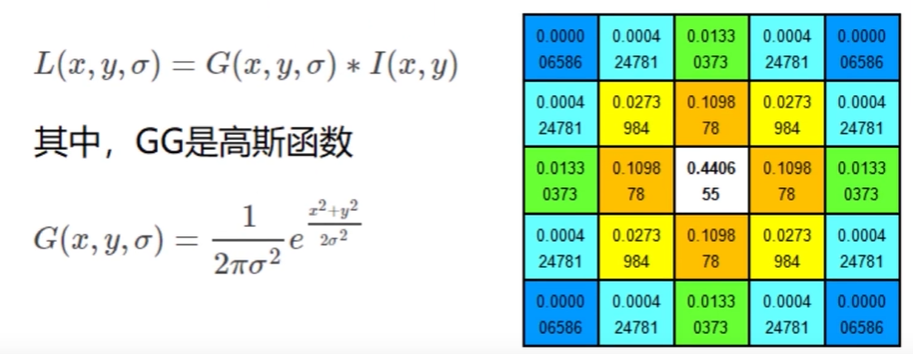
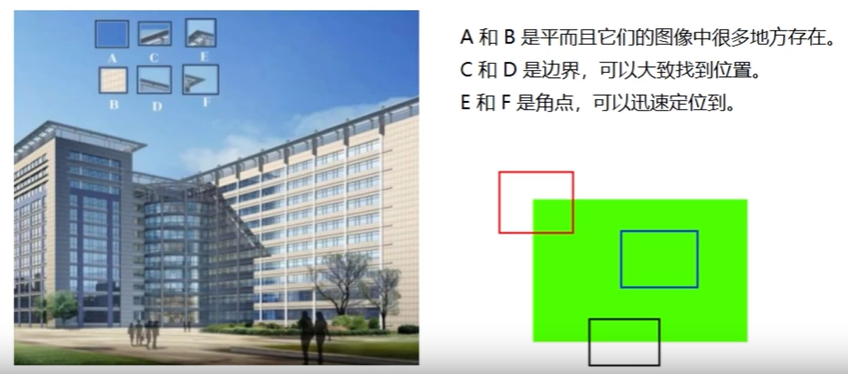
评论 (0)