搜索到
5
篇与
的结果
-
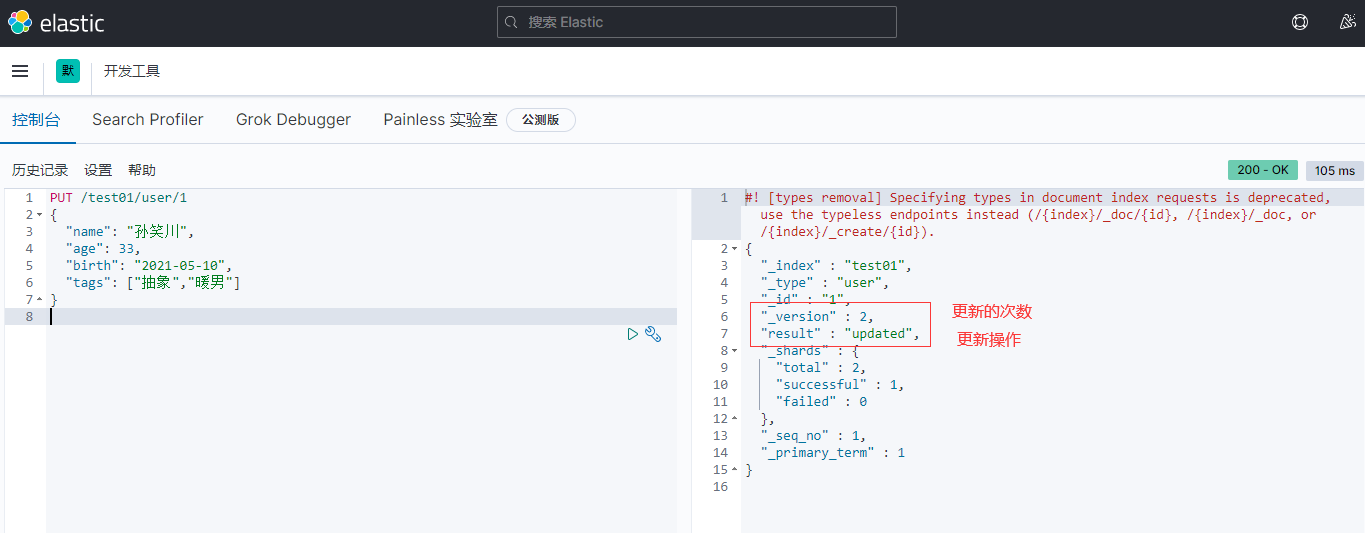
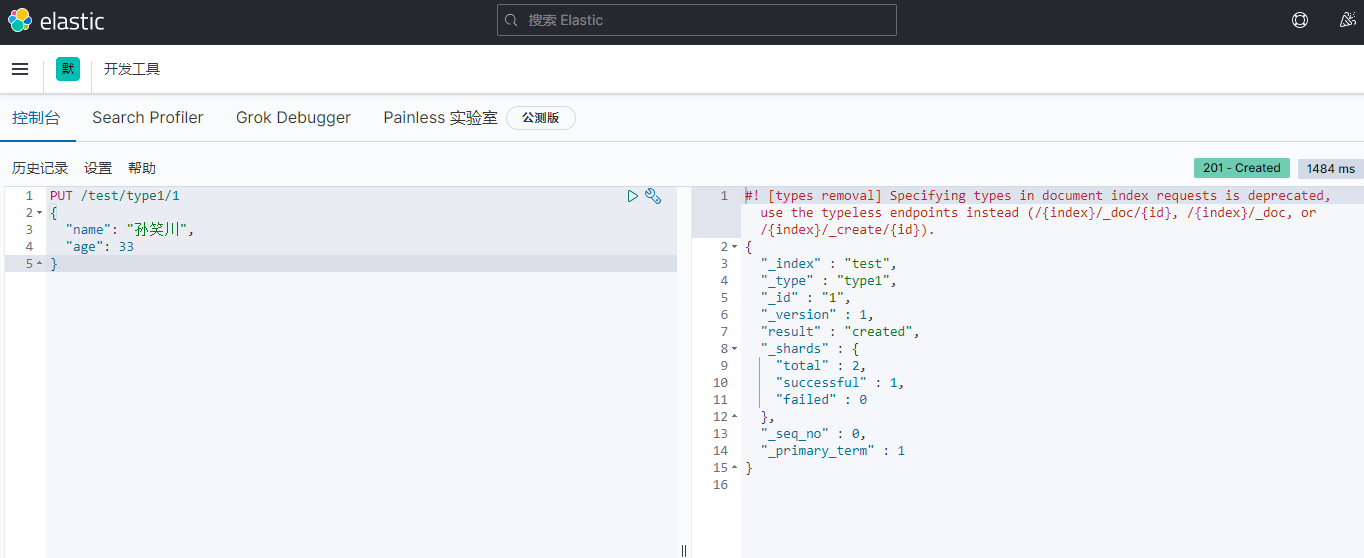
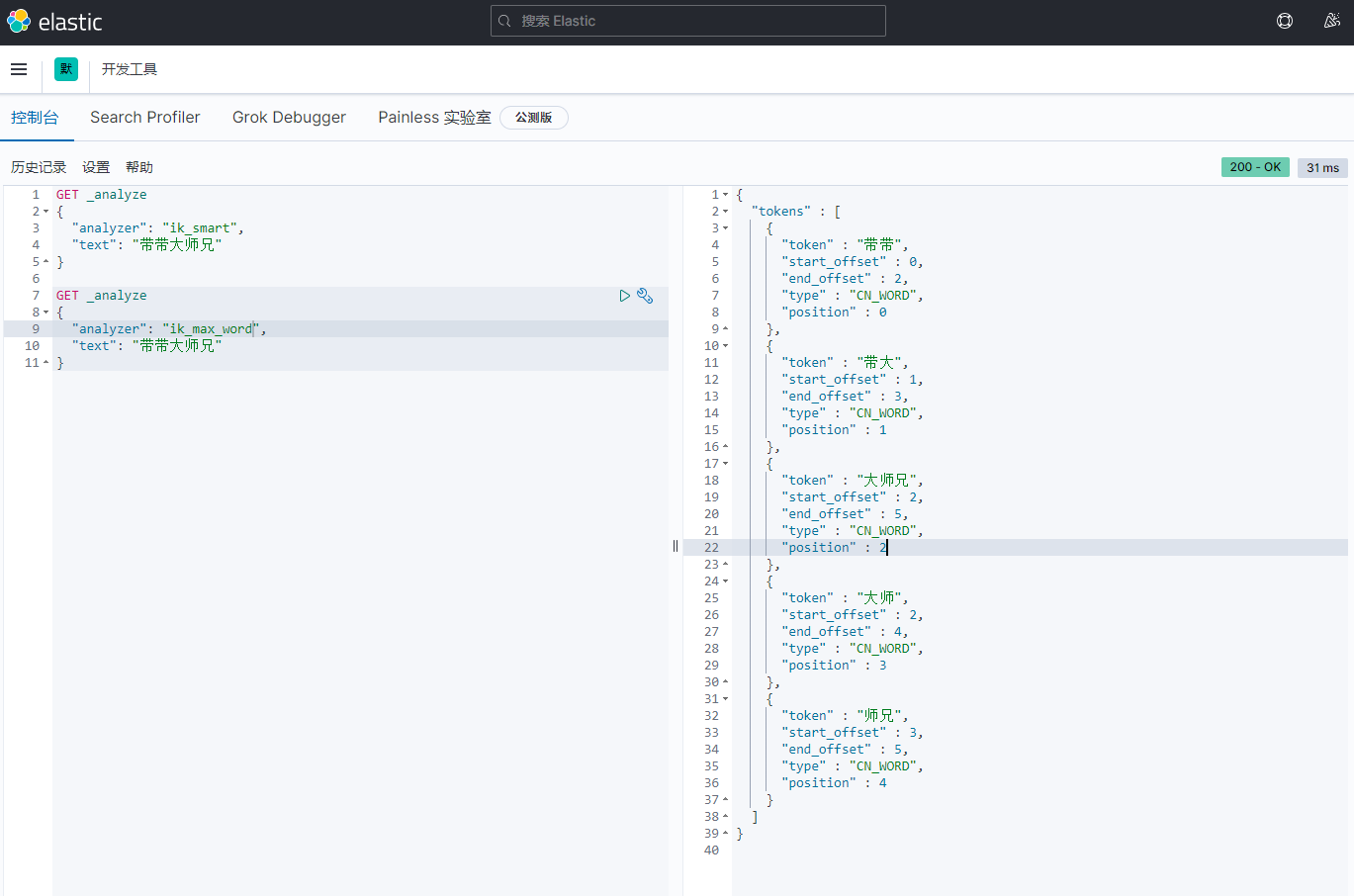
 关于文档的基本操作 基本操作1、添加数据PUT /test01/user/1 { "name": "孙笑川", "age": 33, "birth": "2021-05-10", "tags": ["抽象","带师兄"] }2、获取数据GET /test01/user/13、更新数据 PUT4、POST 更新(推荐使用)5、搜索简单搜索复杂搜索select(排序,分页,高亮,模糊查询,精准查询)//查询参数体使用json构建 GET test01/user/_search { "query": { "match": { "name": "孙笑川" } } }结果过滤:排序:GET test01/user/_search { "query": { "match": { "name": "孙笑川" } }, "sort": [ { "age": { "order": "asc" } } ] }分页: //from等同于pageNum //size等同于pageSize GET test01/user/_search { "query": { "match": { "name": "孙笑川" } }, "sort": [ { "age": { "order": "asc" } } ], "from": 0, "size": 5 }布尔值多条件查询:must (and) 所有的条件都要匹配 where id = 1 and age = 10should (or) 条件匹配 where id = 1 or age = 10must_not (not)过滤器 filtergt # 大于 gte # 大于等于 lt # 小于 lte # 小于等于匹配多个条件精确查询term 通过倒排索引指定的词条进行精确查询分词term 直接精确查询match 查询时会使用分词器解析(先分析文档,再通过分析的文档进行查询)两个类型 text(会被分词器解析) keyword(不会被分词器解析)PUT test02 { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } } PUT test02/_doc/1 { "name": "text keyword字段类型测试", "desc": "text keyword字段类型测试 desc" } PUT test02/_doc/2 { "name": "text keyword字段类型测试", "desc": "text keyword字段类型测试 desc02" } GET _analyze { "analyzer": "keyword", "text": "text keyword字段类型测试" } GET _analyze { "analyzer": "standard", "text": "text keyword字段类型测试" } GET test02/_search { "query": { "term": { "name": "测" } } } GET test02/_search { "query": { "term": { "desc": "text keyword字段类型测试 desc" } } } PUT test02/_doc/3 { "t1": "11", "t2": "2021-05-11" } PUT test02/_doc/4 { "t1": "22", "t2": "2021-05-11" } GET test02/_search { "query": { "bool": { "should": [ { "term": { "t1": "11" } }, { "term": { "t1": "22" } } ] } } }多个值匹配的精确查询高亮查询自定义高亮格式
关于文档的基本操作 基本操作1、添加数据PUT /test01/user/1 { "name": "孙笑川", "age": 33, "birth": "2021-05-10", "tags": ["抽象","带师兄"] }2、获取数据GET /test01/user/13、更新数据 PUT4、POST 更新(推荐使用)5、搜索简单搜索复杂搜索select(排序,分页,高亮,模糊查询,精准查询)//查询参数体使用json构建 GET test01/user/_search { "query": { "match": { "name": "孙笑川" } } }结果过滤:排序:GET test01/user/_search { "query": { "match": { "name": "孙笑川" } }, "sort": [ { "age": { "order": "asc" } } ] }分页: //from等同于pageNum //size等同于pageSize GET test01/user/_search { "query": { "match": { "name": "孙笑川" } }, "sort": [ { "age": { "order": "asc" } } ], "from": 0, "size": 5 }布尔值多条件查询:must (and) 所有的条件都要匹配 where id = 1 and age = 10should (or) 条件匹配 where id = 1 or age = 10must_not (not)过滤器 filtergt # 大于 gte # 大于等于 lt # 小于 lte # 小于等于匹配多个条件精确查询term 通过倒排索引指定的词条进行精确查询分词term 直接精确查询match 查询时会使用分词器解析(先分析文档,再通过分析的文档进行查询)两个类型 text(会被分词器解析) keyword(不会被分词器解析)PUT test02 { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } } PUT test02/_doc/1 { "name": "text keyword字段类型测试", "desc": "text keyword字段类型测试 desc" } PUT test02/_doc/2 { "name": "text keyword字段类型测试", "desc": "text keyword字段类型测试 desc02" } GET _analyze { "analyzer": "keyword", "text": "text keyword字段类型测试" } GET _analyze { "analyzer": "standard", "text": "text keyword字段类型测试" } GET test02/_search { "query": { "term": { "name": "测" } } } GET test02/_search { "query": { "term": { "desc": "text keyword字段类型测试 desc" } } } PUT test02/_doc/3 { "t1": "11", "t2": "2021-05-11" } PUT test02/_doc/4 { "t1": "22", "t2": "2021-05-11" } GET test02/_search { "query": { "bool": { "should": [ { "term": { "t1": "11" } }, { "term": { "t1": "22" } } ] } } }多个值匹配的精确查询高亮查询自定义高亮格式 -
-
-
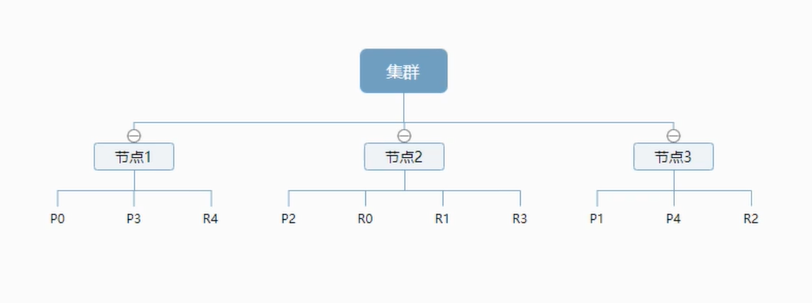
ElasticSearch相关概念 es与关系型数据库对比Relational DBElastic Search数据库(database)索引(indices)表(table)types(类型)(es8.0弃用)行(rows)documents(文档)字段(columns)fieldses(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档又包含多个字段(列)。物理设计:es在后台把每个索引划分成多个分片,每份分片可以在集群中的不同服务器间迁移逻辑设计:一个索引类型中包含多个文档,例如:文档1、文档2,当要搜索一篇文档时,大致流程为:索引 ---> 类型 ---> 文档ID(ID不必是整数,实际上是一个字符串)文档es是面向文档的,也就是说索引和搜索数据的最小单位是文档,其包含有几个重要属性:自我包含,一篇文档同时包含字段和对应的值,即key:value层次型的:一个文档中包含自文档(json对象,fastjson进行自动转换)灵活的结构:文档不依赖预先定义的模式,在关系型数据库中,要提前定义字段才能使用,而在es中,可以忽略一个字段或动态的添加一个新的字段在es中,每个字段的类型非常重要,它会保存字段和类型之间的映射及其他的设置,这种映射具体到每个映射的每种类型,这也是为什么在es中,类型有时候也称为映射类型类型类型是文档的逻辑容器(就像关系型数据库,表格是行的容器),类型中对于字段的定义称为映射,比如name映射为字符串类型。先定义好字段,再使用索引es中的索引就是数据库,索引是映射类型的容器,是一个非常大的文档集合,存储映射类型和其他设置,再被存放到各个分片上物理设计:节点和分片如何工作一个集群至少有一个节点,而一个节点就是一个es进程,创建索引时,默认5个分片(primary shard,主分片),每一个主分片会有一个副本(replica shard,复制分片)以上图3个节点的集群为例,可以看出主分片和对应的复制分片都不会在同一个节点内,可以避免级联故障。实际上,一个分片是一个Lucence索引,一个包含倒排索引的文件目录,倒排索引使得es可以在不扫描全部文档的情况下,检索出需要的内容。倒排索引es使用的是倒排索引结构,采用Lucence倒排索引作为底层。这种结构适用于快速全文搜索,一个索引由文档中所有不同的列表构成,对于每一个词,都有一个包含它的文档列表。例1:现在有两个文档,每个文档包含以下内容:# 文档1 Study every day,good good up to forever # 文档2 To forever,study every day, good good up为了创建倒排索引,先要将每个文档拆分成独立的词(或称为词条、tokens),然后创建一个包含所有不重复的词条的排序列表 文档1文档2Study√×To×√every√√forever√√day√√study×√good√√every√√to√×up√√现在试图搜索to forever,只需要查看包含每个词条的文档 文档1文档2to√×forever√√total21两个文档都匹配,但第一个文档比第二个文档匹配度更高,没有别的条件时,返回这两个包含关键字的文档例2:通过博客标签来搜索博客文章现搜索包含python标签的文章,相较于搜索原始数据,现只需要搜索标签这一栏,即可更快的获取文章id
-
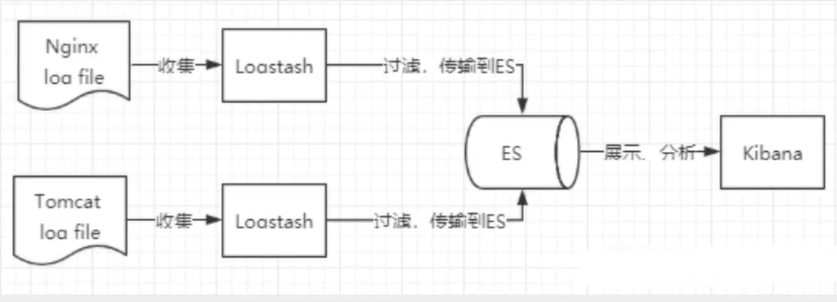
Elastic Search 一、概述Elastic Search简称es,是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据,可以使用java开发并使用Lucence作为其核心来实现所有索引和搜索的功能,其目的是通过简单的RESTfull API来隐藏Lucence的复杂性,从而让全文搜索变得简单。二、ELKELK是Elastic Search、Logstash、Kibana的首字母简称,也成为Elastic Stack。其中Elastic Search是一个基于Lucence、分布式、通过Restfull方式进行交互的近实时搜索平台框架;Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/rdis/elasticsearch/Kafka等);Kibana可以将elasticsearch的数据通过友好的页面展示出来。提供实时分析的功能。三、安装1、elasticsearch官网地址:https://www.elastic.co/cn/elasticsearch/# 跨域问题须在/config/elasticsearch.yml配置文件末尾添加 http.cors.enabled: true http.cors.allow-origin: "*"2、Kibana官网地址:https://www.elastic.co/cn/kibana注意:es和kibana的版本必须一致